发现写满了注释就没啥好说的了,姑且称为教程吧。
需要自己操作的核心只是$regex_item和$regex_item2这两个正则的修改。如有兴趣,可另开教程。
聪明的你可能会发现这两个匹配的内容不是一样的吗,那为什么不合二为一呢?
自己体会。
例一:微博热搜
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
<?php include "gethtml.php"; $title_find[0]=$link_find[0]=$des_find[0]='#/[\x00-\x08\x0b-\x0c\x0e-\x1f]/s#'; $title_replace[0]=$link_replace[0]=$des_replace[0]=''; $footer='</channel></rss>'; //以上为一些初始工作,不用管。 $header='<?xml version="1.0" encoding="utf-8"?><rss version="2.0"><channel><title>热搜</title>';//修改RSS名称 $html=gethtml('https://s.weibo.com/top/summary');//要操作的网页。 $html=strpos($html,'charset=gb')===false?$html:iconv('GB2312','UTF-8//IGNORE',$html);//古董网页专用:( $regex_item = '#<td class="td-02">.+?td>#s';//正则规则在井号中间,s代表可匹配多行,否则只匹配单行,具体要看网页源代码。 $regex_item2 = '#.*?<a href="(?<link>.+?)" target="_blank">(?<title>.+?)</a>.*#s'; if(preg_match_all($regex_item, $html, $items)){//在已经抓下来的网页中匹配"代码块",每一"块"的原则是结构高度统一且必须包含链接、标题。概要可无,因为可以用标题替代。 //print_r($items[0]);//调试用,如需调试,把最前面的双斜杠去掉。 foreach($items[0] as $item){ if(preg_match($regex_item2,$item)){ $rss.=preg_replace_callback( $regex_item2,//对"块"分组捕获链接、标题、摘要并命名。 function ($matches) { global $title_find,$title_replace,$link_find,$link_replace,$des_find,$des_replace; //以下可对title进行替换操作,酌情增减。 $title_find[1]='#的#'; $title_replace[1]='の'; $title_find[2]='#百度#'; $title_replace[2]='一个无耻的网站'; //以下对link进行替换操作,酌情增减。此例增加网站域名,否则链接无效。 $link_find[1]='#(.+)#'; $link_replace[1]='https://s.weibo.com$1'; //以下可对description进行替换操作,酌情增减。此例并无任何操作。 $title=preg_replace($title_find,$title_replace,$matches['title']);//根据上面规则替换后输出title。$matches['title']为上面分组捕获的内容。 $link=preg_replace($link_find,$link_replace,$matches['link']);//根据上面规则替换后输出link。 $des=preg_replace($des_find,$des_replace,$matches['title']);//根据上面规则替换后输出description。 //以下就是一条最基本的RSS内容了。\n和\t只是格式化了代码,并无大用,方便查错。 return "<item>\n\t<title><![CDATA[".$title."]]></title>\n\t<link><![CDATA[".$link."]]></link>\n\t<description><![CDATA[".$des."]]></description>\n</item>\n"; }, $item ); } } //echo $rss;//调试用 //大功告成,输出收工。 file_put_contents('weibotop.xml',$header.$rss.$footer); } ?> |
图一,此为表达式$regex_item匹配内容,即所谓结构统一且必包含所需元素。
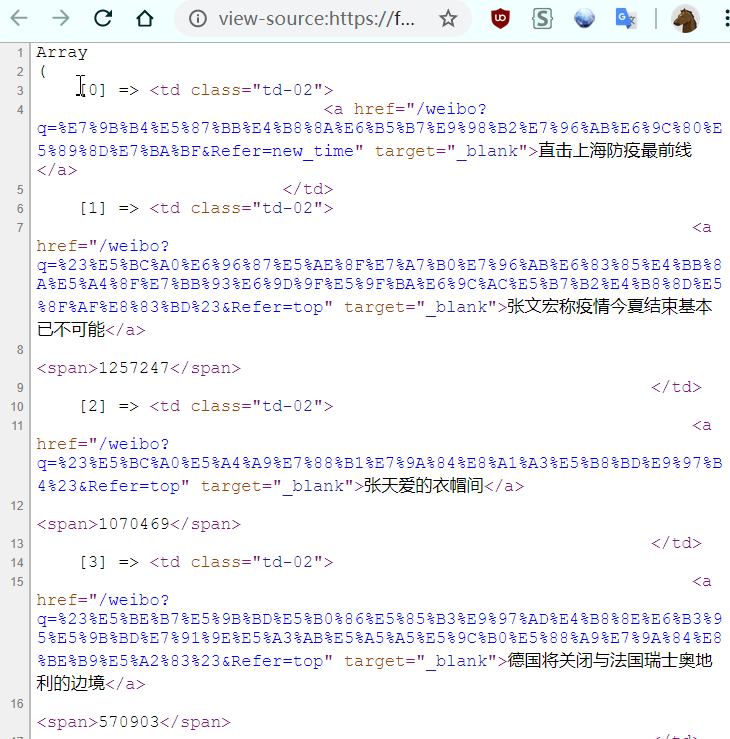
例二:百度知道9图轮播
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<?php include "gethtml.php"; $title_find[0]=$link_find[0]=$des_find[0]='#/[\x00-\x08\x0b-\x0c\x0e-\x1f]/s#'; $title_replace[0]=$link_replace[0]=$des_replace[0]=''; $footer='</channel></rss>'; //以上为一些初始工作,不用管。 $header='<?xml version="1.0" encoding="utf-8"?><rss version="2.0"><channel><title>百度知道</title>';//修改RSS名称 $html=gethtml('https://zhidao.baidu.com/');//要操作的网页。 $html=strpos($html,'charset=gb')===false?$html:iconv('GB2312','UTF-8//IGNORE',$html);//古董网页专用:( $regex_item = '#<a href="(.+?)" target="_blank" class="banner-card-item".*?a>#s';//正则规则在井号中间,s代表可匹配多行,否则只匹配单行,具体要看网页源代码。 $regex_item2 = '#<a href="(?<link>.+?)".+?class="title">(?<title>.+?)</div>.+?class="intro">(?<des>.+?)<.*#s'; if(preg_match_all($regex_item, $html, $items)){//在已经抓下来的网页中匹配"代码块",每一"块"的原则是结构高度统一且必须包含链接、标题。概要可无,因为可以用标题替代。 //print_r($items[0]);//调试用。如需调试,把最前面的双斜杠去掉。 foreach($items[0] as $item){ if(preg_match($regex_item2,$item)){ $rss.=preg_replace_callback( $regex_item2,//对"块"分组捕获链接、标题、摘要并命名。 function ($matches) { global $title_find,$title_replace,$link_find,$link_replace,$des_find,$des_replace; //以下可对title进行替换操作,酌情增减。 $title_find[1]='#的#'; $title_replace[1]='の'; $title_find[2]='#百度#'; $title_replace[2]='一个无耻的网站'; //以下对link进行替换操作,酌情增减。此例无任何操作。 //以下可对description进行替换操作,酌情增减。此例并无任何操作。 $title=preg_replace($title_find,$title_replace,$matches['title']);//根据上面规则替换后输出title。$matches['title']为上面分组捕获的内容。 $link=preg_replace($link_find,$link_replace,$matches['link']);//根据上面规则替换后输出link。 $des=preg_replace($des_find,$des_replace,$matches['des']);//根据上面规则替换后输出description。 //以下就是一条最基本的RSS内容了。\n和\t只是格式化了代码,并无大用,方便查错。 return "<item>\n\t<title><![CDATA[".$title."]]></title>\n\t<link><![CDATA[".$link."]]></link>\n\t<description><![CDATA[".$des."]]></description>\n</item>\n"; }, $item ); } } //echo $rss;//调试用 //大功告成,输出收工。 file_put_contents('zhidao.xml',$header.$rss.$footer); } ?> |
两个例子应该够用了,举一反三吧。
代码下载:http://feedx.net/rss/tutorial/tutorial200316.tgz
对于小白来说,希望能有详细的视频教程,谢谢了
感谢!不过我不太习惯这种写在一起的正则,头大了,而且我试了写了下,有点麻烦,容易出奇怪的问题,比如你这个微博热搜的就出问题了(我没有修改代码),你可以自己测试下。我运行的结果http://209.250.231.104/rss/weibotop.xml 。
其实我觉得分开写比较好吧,我比较习惯分开,直接抓网页源代码暴力匹配,因为再怎么复杂也有规律,比如微博热搜
标题:td-02\”>\n.*(.*)
小括号内的为匹配内容
我测试是51条结果(没有遗漏),标题和链接一一对应,再用正则替换就完美了,只是我不会写代码
我写的正则匹配:http://209.250.231.104/rss/1.png 直接贴文字有问题
程序稍微改改就正常了,少了一步判断。
但程序流程应该就是这样了。
OK!已经搞定了!感谢
我还没试,但是做好了xml,用什么订阅呢?feedx还是rsshub投稿?我没自建哈。
PS,怎么网站不能登陆了,没看到登陆选项
登录要看缘分,哈哈
谢谢站长,已收录本文到我频道。
可以帮忙做这个网站的军事栏目吗站长http://www.ifeng.com/
https://feedx.net/read?r=ifengmil
这两个例子没有看到输出全文,希望能有一个复杂一点的案例,谢谢
不用仔细找,本站内容本来就不多,全文的教程也有。
RSS遗老遗少,感谢站长的无私奉献。
站长有没有抓取「观察者」网的计划?谢谢
站长你好,请问这个需要怎么部署?本人小白,不是太懂
还是需要基本的PHP环境的,倒也不贵,原来godaddy上域名+主机空间一年只需要$10,不知道现在还有没有。
真的辛苦了。原来都是用fivefilters,感觉你的技术更好。
不知道,知乎这类的能不能做?或者股票公告信息更新之类的,类似雪球上面个订阅一个更新。这种做起来其实面更广一点。对于大家的网站都好。
太难了,我连怎么部署都不会
不知道有没有参考消息和经济观察报的,我很喜欢这两张报